Overview Of Peer To Peer Replication In SQL Server

Introduction
Peer to Peer replication in SQL server is used for enhancing the availability of data by maintaining number of replicas of database across different server instance also known as nodes. It enables applications to perform read operation from different nodes and this technique also scales out read operation. The changes made on one node is circularized to all nodes, if the user will made any insert, update and delete operation on single node will be propagated to all other nodes.
Terms used in SQL Server Peer Peer Replication
There are generally three terms used in replication i.e Publisher, Subscriber and Distributor:
Publisher
It is a main original database that contains the actual data and it contains data to replicate.
Subscriber
There can be number of subscribers of single publisher. They are the replicas of Publisher database.
Distributor
This will propagates the transaction or changes across the subscriber database.
More About Peer Peer Replication And It’s Architecture
The concept used in peer to peer replication is same as transaction replication that circulates transaction data across multiple nodes. However in Peer to peer replication each node is treated as a publisher as well as subscriber that means, they can send and receive transaction to each other to synchronize data across all the nodes.
Discussing the Architecture
There can be any number of nodes connected with each other to fulfill the request sent by application server.
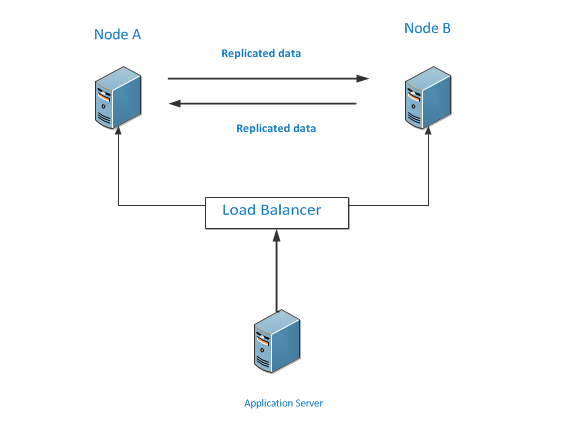
Architecture of Two Nodes
In this type of nodes setup, application server will send a request to both the nodes. Node A and Node b will replicates it’s data to each other, when connected with either of nodes, the application server will get the consistent result.
The bi-directional replication is takes place between publisher and subscriber known as Peer to Peer Replication.
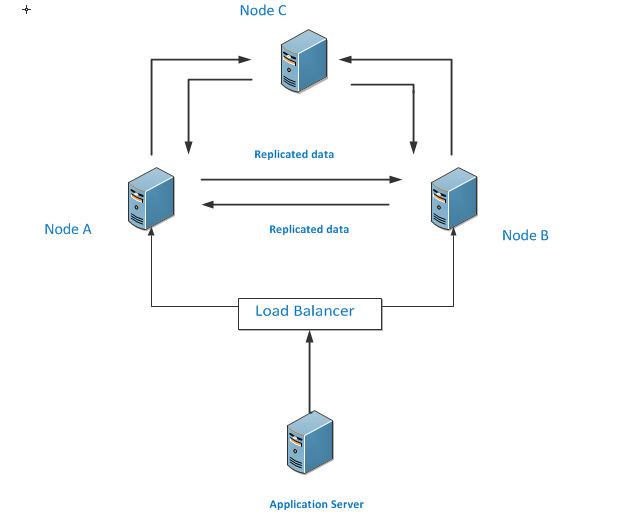
Architecture of Three Node
The three nodes replication is also same as two nodes where each node is replicating the transactions to have same data on each nodes. If any node is not working ,the application still remains functional.
There is one more scenario, where there is a separate application server present for each node and each application server is performing different transaction at their end , these operations will also being replicated to all existing nodes.
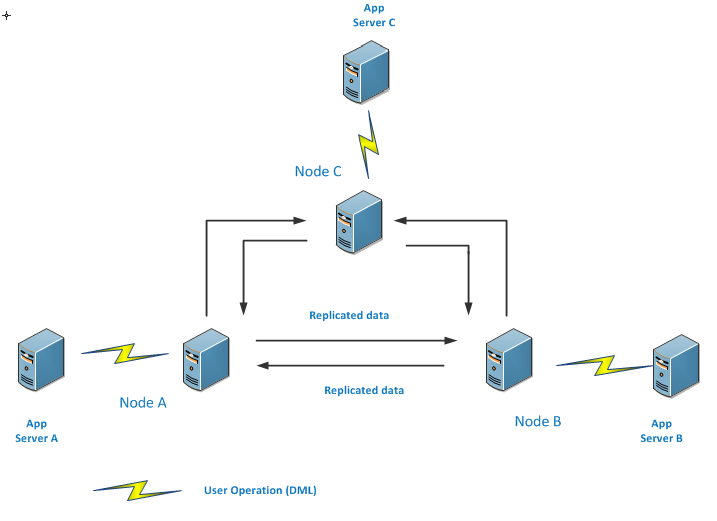
We can say that the main purpose of peer to peer replication in SQL Server is to keep each node updated when any transaction will takes place in database.
Conflicts in Peer to Peer Replication
With Peer to Peer replication, application server can perform different transactions such as insert, update and delete at any node and the changes that have been made are propagated to other existing nodes. However, the change made on one node and the change made on other node could conflict each other. The conflict is a state that keeps topology in an inconsistent state.
When talking about single database, if all applications makes changes on same row does not cause any conflict. But in case of distributed database, if the row is modified at number of nodes, it can results conflict state.
In order to prevent this issue, one should enable the Conflict Detection option and until the issue is not resolved topology will remains in inconsistent form.
There is also a way to ignore conflict and continue replicating transaction which can be done with the help of Sp_configure_peerconflictdetection pocedure. Admin can also configure Conflict Detection Alert that will alert the user when the conflict will occur.
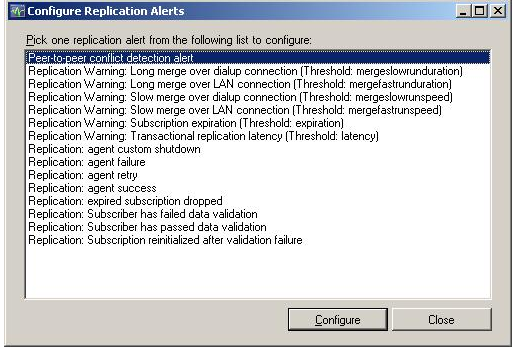
How to Configure Conflict Detection Alerts
-
- Go to Publication
- Right click on publication and select “Launch Replication Monitor”
- Now search for P2P publisher and go to the warning tab
- In Warning tab, select Conflict Alerts
- Click Configure
Conclusion:
Peer to peer replication in SQL Server is an efficient way to enhance the availability of data by keeping the replica of database on different nodes. Application server can easily perform read operation as well as operations like insert, update and delete on these node. However, user may face situation of conflict while accessing data from these nodes, but user can prevent this situation by enabling the conflict detection option.